
Avanzando en el poder de la analítica
- Detalles
- Categoría: Minitab
- Visto: 5515

El beneficio potencial de los datos almacenados en servidores es enorme. Los bancos, empresas de seguros, telefónicas, fabricantes - de hecho las organizaciones de todas las industrias necesitan aprovecharse los datos de que disponen para mejorar sus operaciones, comprender mejor a sus clientes y encontrar una ventaja competitiva.
Con la llegada de la Industria 4.0 y la Internet industrial de las cosas (IIoT), la información llega fluyendo desde muchas fuentes — desde equipos en líneas de producción, sensores en productos, datos de ventas y mucho más. Ser capaz de recoger, cotejar y analizar esta información se está haciendo incluso más crítico a medida que lasa empresas los utilizan para encontrar mayor conocimiento de sus procesos y mejorar la eficiencia y efectividad.
Esta situación representa una cantidad masiva de nuevas oportunidades, pero también trae algunos retos significativos.
Nuevos retos
La gran cantidad de datos producidos desde estos sistemas modernos actuales presentan retos únicos no vistos con los conjuntos de datos más pequeños. Estos conjuntos de datos pueden contener un gran número de predictores, un gran número de filas, o ambos. También es habitual para los datos observacionales como estos que sean más complejos que lo que se podía encontrar con datos obtenidos de experimentos diseñados cuidadosamente.
Este artículo describe cómo afectan estos asuntos al análisis de datos.
Gran número de predictores
Las herramientas de modelado estadístico tradicionales, como la regresión y la regresión logística, se basan en los p-valores para detectar efectos significativos. Específicamente, a menudo queremos que un predictor con un p-valor menor que 0.05 sea estadísticamente significativo. Sin embargo, este valor de referencia de 0.05 significa que estamos de acuerdo con una tasa de error del 5%, o que un predictor de cada veinte será significativo solo por casualidad. Con muchos predictores, confiar en los p-valores puede generar un modelado de ruido aleatorio.
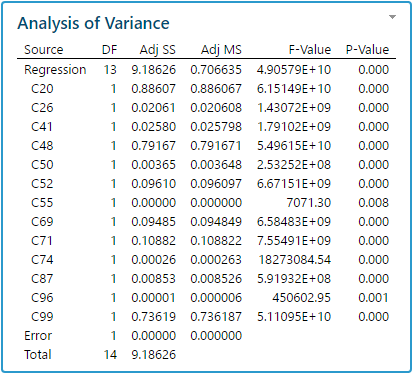
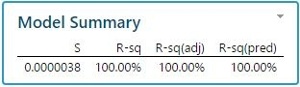
Para ilustrar esto, hemos simulado aleatoriamente 100 columnas, normalmente distribuidas, con 15 observaciones cada una. Una regresión por pasos muestra que no menos de 13 columnas de 99 variables tienen un efecto estadísticamente significativo en la última columna (valores P muy cercanos a 0) y el valore del cuadrado de R es extremadamente alto (100%). Obviamente todos estos son efectos espurios causados exclusivamente por fluctuaciones aleatorias (ver los resultados a continuación).
Gran cantidad de observaciones: Potencia vs. significancia práctica
Tamaños de muestra muy grandes mejoran la potencia y la capacidad de detectar términos estadísticamente significativos incluso cuando son (muy) pequeños, sin embargo, tales efectos estadísticamente significativos no implican necesariamente una significancia práctica. Con grandes conjuntos de datos, el P-valor puede llegar a ser demasiado sensible a efectos pequeños pero reales que conduzcan a un modelo final muy complejo que contenga la mayoría de los potenciales predictores iniciales.
Aunque estos términos pueden ser estadísticamente significativos, la mayoría de ellos en realidad tienen poca significancia práctica.
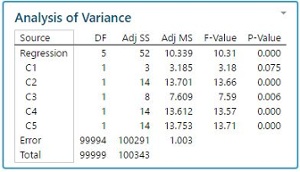
Para ilustrar esto, se simularon 6 columnas con 100000 observaciones cada una. Se introdujo un modelo para que las 5 coumnas de entrada tuvieran un pequeño efecto en la última columna (impacto real pero muy pequeño). El R cuadrado es, comprensiblmente, extremadamente pobre (cerca del 0%), pero los P- valores indican que los efectos son muy significativos desde una perspectiva estadística (ver los resultados a continuación).
Complejidad debida a efectos no lineales, así como valores atípicos y perdidos
En un rango más amplio y en un periodo de tiempo prolongado, es probable que las variables sigan patrones no lineales. Es más probable que los valores perdidos y los valores atípicos estén presentes en grandes conjuntos de datos y afecten a la eficiencia de herramientas de modelado estadístico (debido a un único valor perdido, por ejemplo, la fila completa de observaciones podría no ser tenida en cuenta).
Típicamente, un banco que intenta identificar transacciones fraudulentas necesitará analizar una gran cantidad de predictores y observaciones, con muchos efectos complejos no lineales, valores perdidos y valores atípicos, lo mismo para un centro de producción que busque identificar detractores del rendimiento, o para una empresa demonitorización de registros de equipos de mantenimiento para evitar fallos.
Minería de datos y análisis predictivo
Las potentes herramientas de aprendizaje automático como CART, Random Forests, TreeNet Gradient Boosting, y Multivariate Adaptive Regression Splines son una útil adición al juego de herramientas de cualquier practicante, especialemente cuando se enfrentan a conjuntos de datos más grandes. Estas técnicas basadas en reglas se ven menos afectadas por limitaciones que ese han descrito anteriormente, ya que no se basan en p-valores de umbrales de significación estadística y se basan en árboles de decisión con reglas IF, AND, O que también aislarán valores atípicos e "imputarán" valores perdidos.
Por supuesto, los días de los conjuntos de datos pequeños y medianos están lejos de haber terminado. Las herramientas estadísticas inteligentes como los diseños de experimentos y otras herramientas de modelado estadístico seguirán siendo populares entre los ingenieros de procesos, I+D, calidad o validación, para optimizar las herramientas o procesos. Los Black Belts y Master Black Belts continuarán implementando herramientas de análisis de datos Six Sigma para el análisis de causas raíz, la calidad y la mejora de la eficiencia en todos los niveles, en toda la empresa, utilizando P-valores para identificar preditores que sean estadísticamente significativos.
Conclusión
A medida que avanzamos en un futuro que requiere que las organizaciones extraigan información a partir de una cantidad cada vez mayor de datos, se vuelve incluso más imporatne garantizar que se elijan las herramientas correctas para poder analizar datos de diferentes tamaños y complejidad.
Las modernas herramientas de aprendizaje automático como CART, TreeNet, Random Forests y MARS proporcionan una excelente opción para grandes datos y/o relaciones más complejas, mientras que las técnicas de modelado más tradicionales como la regresión continuarán siendo las herramientas preferidas cuando se cumplen los supuestos del modelo y el objetivo es encontrar una ecuación simple e interpretable.
Los enfoques tanto de la estadística como del aprendizaje automático juegan un papel fundamental en la búsqueda de inteligencia procesable, y será la colaboración y la comunicación entre estas dos disciplinas impulsadas por los datos lo que permitirá a las organizaciones tomar mejores decisiones y obener una ventaja competitiva.
Para los clientes en ruta hacia el manejo de grandes conjuntos de datos complejos, la oferta de productos Minitab ha evolucionado integrando una plataforma rápida y altamente precisa para minería de datos y análisis predictivo que incluye CART, Treenet Gradient Boosting, MARS y otras metodologías.